Przewodnik po programie Weasel
Wprowadzenie
Działający pod systemem operacyjnym Windows program Weasel (łasica) jest prostą prezentacją ewolucyjnego (genetycznego) algorytmu i służy do badania komputerowych symulacji ewolucyjnych procesów. Został on stworzony przez Lesa Ey i Dona Battena z Answers in Genesis. Algorytm ewolucyjny Weasel powstał na bazie słynnej symulacji autorstwa znanego oksfordzkiego biologa i popularyzatora teorii ewolucji, Richarda Dawkinsa. W swojej książce Ślepy zegarmistrz opisał on taką symulację jako ilustrację potęgi doboru kumulatywnego. Symulator Weasel nie tylko dokładnie odwzorowuje symulację autorstwa Dawkinsa, ale posiada wiele dodatkowych opcji i funkcji, które wprowadzają do niej nieco biologicznego realizmu. Są to m.in. określanie tempa mutacji, ich rodzajów, liczby potomstwa itp. Program zawiera także opcję ewolucji projektowanej przez użytkownika sekwencji aminokwasowych opartych na odpowiednich kodonach DNA. Program Weasel przez swoją prostotę, intuicyjność i wielofunkcyjność jest doskonałym narzędziem dla wszystkich zainteresowanych algorytmami genetycznymi — zarówno początkujących, jak i pasjonatów, w prosty sposób demonstrując fałszywość zapewnień, że ewolucyjne algorytmy potwierdzają teorię ewolucji.
Rzut oka na interfejs programu
Po ściągnięciu, rozpakowaniu i zainstalowaniu (przez Setup) programu Weasel możemy przystąpić do symulowania wirtualnych ewolucji. Po otwarciu programu pokaże się nam okno, w którym na początek najważniejsze są następujące miejsca.

|
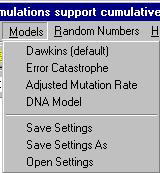
Klasycznie, na górze będzie kilka pozycji menu, a w nim następujące funkcje:
"Demonstration", gdzie uruchamiamy, pauzujemy lub zatrzymujemy symulację (te same funkcję pełnią klawisze, o czym niżej).
"Edit”, gdzie m.in. możemy wywołać okno dialogowe do projektowania własnej sekwencji aminokwasów ("Target Peptide").
"Models”, gdzie wybieramy cztery podstawowe modele symulacji (Model Dawkinsa, Model katastrofy błędów, Model realistycznego tempa mutacji i Model DNA — o tych modelach patrz niżej).
Niżej widzimy przyciski powtarzające funkcje z menu "Demonstration". Czyli mamy po kolei: "Start run" (F2, start symulacji), "Step throught one generation" (F3, przycisk ten pozwala ręcznie przeskakiwać od generacji do generacji), "Pause run" (F4, pauza w symulacji) i "Stop run" (F5, czyli zatrzymanie całej symulacji). Kolejny przycisk ("Tutorial") otwiera okno z angielskimi opisami programu.
Tuż pod tymi przyciskami jest okno "Target", czyli miejsce gdzie wpisujemy docelową alfabetyczną sekwencję. Jeszcze niżej jest okno raportu, gdzie możemy obserwować przebiegającą symulację. Program pokazuje i numeruje kolejne generacje, mutacje wyświetlane są na czerwono, a pogrubiane te litery (lub aminokwasy), które znalazły się na właściwej pozycji. Poza tym są jeszcze dwa panele: Panel Wskaźników pod oknem wyświetlającym przebieg symulacji, który pozwala śledzić kilka istotnych parametrów w symulowanych ewolucjach i Panel Ustawień po prawej stronie od głównego okna, gdzie możemy zmieniać szereg ustawień symulacji.
Program obejmuje cztery, wspomniane wyżej, zasadnicze modele ewolucji: Model Dawkinsa, Model katastrofy błędów, Model realistycznego tempa mutacji i Model DNA. Dodatkowo Panel Ustawień pozwala wprowadzać dodatkowe zmiennie do każdego modelu i w ten sposób go urozmaicać. Poniższy Przewodnik omawia najpierw cztery podstawowe modele symulacji, następnie wyjaśnia funkcje Panelu Ustawień, by na zakończenie opisać Panel Wskaźników. Rozpocznijmy od czterech podstawowych modelów wirtualnej ewolucji.
Główne modele symulacji
Dawkins (default) (Model Dawkinsa)
|
W tym modelu docelowa sekwencja i parametry symulacji są dokładnie takie same jak w oryginalnym programie Dawkinsa. W symulacji Dawkinsa celem "ewolucji" jest zadany z góry ciąg liter. Dawkins wybrał zdanie z poematu Williama Szekspira METHINKS IT IS LIKE A WEASEL (Zdaje mi się, że jest podobniejsza do łasicy). Jak łatwo zauważyć, ten "organizm" składa się z 23 liter i pięciu spacji. W symulacji tej komputer generuje przypadkowy ciąg liter reprezentujących wyjściowy "organizm". Ta sekwencja zawsze zawiera dokładnie taką samą liczbę liter jak sekwencja docelowa. Ta pierwsza sekwencja jest następnie powielana do 100 kopii — każda "generacja" zawiera właśnie 100 takich sekwencji, czyli "organizmów". Następnie w każdej z tych 100 sekwencji następuje jedna przypadkowa "mutacja" w przypadkowym miejscu, polegająca na zastąpieniu jakiejś litery inną (substytucja). Teraz, co jest rzekomo analogiczne do doboru naturalnego, każda taka sekwencja jest testowana w celu określenia, która jest najbardziej zbliżona do docelowej sekwencji METHINKS IT IS LIKE A WEASEL. Jedna (tylko jedna) z tych 100 sekwencji, która najbardziej przypomina docelowe zdanie jest selekcjonowana do dalszej "ewolucji". Ta najbardziej obiecująca sekwencja jest następnie znowu kopiowana do 100 "osobników". I znowu każda z tych 100 sekwencji podlega przypadkowej "mutacji", a sekwencja najbardziej zbliżona do docelowej jest selekcjonowana, by stała się wyjściową dla kolejnej "generacji" — co ma reprezentować reprodukcję. Trwa to tak długo, aż wszystkie litery znajdą się na właściwych pozycjach. Symulacja ta ma ilustrować ewolucję przez dobór kumulatywny faworyzujący korzystne mutacje.
Model ten ustawiamy wchodząc do "Models" i klikając na "Dawkins model (default)". Uruchamiając ten program, dojdzie on do docelowej sekwencji zwykle w 30-60 generacjach (iteracjach). Ponieważ dojście do docelowej sekwencji zależy jednocześnie od przypadkowo dobranej sekwencji początkowej, jak i przypadkowych mutacji, rezultaty mogą się nieco różnić w każdej turze. Jedynym dodatkiem do oryginalnego programu jest opcja Generation Time (w prawym dolnym rogu okna programu; na temat tej opcji patrz niżej, w Panelu Ustawień). Tutaj może być wprowadzony czas trwania (w latach, dniach, godzinach lub w minutach) każdej generacji. Program następnie przelicza czas jaki upłynął, aby symulacja dotarła do docelowej sekwencji i wyświetla go w panelu na dole okna ("Years" — o tym panelu czytaj niżej, w dziale Panel Wskaźników).
W tym modelu wyjściową sekwencją jest ta zaczerpnięta z symulacji Dawkinsa, czyli słynne METHINKS IT IS LIKE A WEASEL, ale możemy oczywiście wprowadzać własne frazy dowolnej długości. Sekwencja taka musi się składać z liter od A do Z (duże lub małe litery, ale bez polskich znaków) oraz ze spacji. Znaki interpunkcyjne można wstawiać, ale program pominie je w symulacji, zostawiając tylko litery i spacje.
Error Catastrophe (Model katastrofy błędów)
Katastrofa błędów zdarza się gdy genetyczna informacja jest niszczona przez mutacje takie, które powodują, że kolejne generacje są gorzej przystosowane niż ich rodzice, tak więc dobór nie może zachować integralności genomu i w efekcie docelowa sekwencja nie może zostać osiągnięta. Model ten wybieramy zaznaczając "Error Catastrophe" z menu "Models".
W modelu katastrofy błędów liczba potomstwa w każdej generacji (Offspring Count w Panelu Ustawień) jest po prostu zredukowana od 100 do 10; wszystkie inne parametry pozostają zaś takie same jak w modelu Dawkinsa. Ponieważ liczba potomstwa jest mniejsza, szansa wystąpienia pożądanej mutacji zdarzającej się przynajmniej w jednej generacji jest mniejsza. Ponadto, jak pokazują wyniki tego modelu, prawdopodobieństwo wystąpienia szkodliwej mutacji wzrasta do punktu gdzie jest równe prawdopodobieństwu powstania pożądanej nowej mutacji. Tak więc taka symulacja nie osiągnie wyniku — dochodzi ona zwykle do pewnego punktu, po czym grzęźnie w katastrofie błędów.
Użytkownik może także sam wywołać katastrofę błędów przez zwiększanie tempa mutacji. Robi się to przez wybranie opcji no w Guarantee Mutation? (na temat tej opcji patrz niżej, w Panelu Ustawień). Jedna mutacja w 6 literach na generację powoduje katastrofę błędów w około 100 generacjach. Model ten pokazuje ważną rzecz — im dłuższa docelowa sekwencja liter (lub łańcuch aminokwasów, gdy wybierzemy Model DNA) tym tempo mutacji — by uniknąć katastrofy błędów — musi być proporcjonalnie mniejsze.
By uniknąć katastrofy błędów, tempo mutacji musi być odwrotnie proporcjonalne do długości ewoluującego genomu. Im większy jest genom, tym mniejsze musi być tempo mutacji. Zobaczcie to sami odpowiednio zwiększając tempo mutacji. Efektem nie będzie szybsza ewolucja, ale przeciwnie — symulacja ugrzęźnie w katastrofie błędów.
Dla przykładu, modelując ewolucję DNA (Model DNA) z małą liczbą potomstwa ustawioną powiedzmy na 10, tempo mutacji zastępujących (substytucji — o ustawieniach rodzajów mutacji patrz niżej, w Panelu Ustawień) nie może być wiele większe niż długość docelowej sekwencji. Przykładowo jeśli docelową sekwencję stanowi 33 aminokwasów (99 kodonów), tempo mutacji 1 na 35 (1/35) spowoduje katastrofę błędów. Model ten pokazuje kolejne nierealistyczne założenie w symulacji Dawkinsa — aby symulacja osiągnęła cel, konieczne jest m.in. zachowywanie równowagi pomiędzy liczbą liter w docelowej sekwencji (28 liter i spacji) a tempem mutacji — 1/28 (1 na 28). Popróbujcie sami zmieniać tempo mutacji i wybierać ich rodzaje — o tym niżej, w dziale Panel Ustawień.
Adjusted mutation rate (Model realistycznego tempa mutacji)
Wyżej wspomniano, że tempo mutacji nie może być znacznie większe niż jedna w genomie na generację. To kolejne ograniczenie nałożone na ewolucyjny proces — nawet przy założeniu o idealnej selekcji. Tempo mutacji zachodzących w realnym świecie są wiele rzędów mniejsze niż to użyte w symulacji Dawkinsa i innych symulacjach ewolucji — także w omawianym programie.
Tempo mutacji u bakterii dla jednego nukleotydu sytuuje się pomiędzy 0,1 i 10 na miliard transkrypcji. Ale u innych form życia to tempo jest mniejsze. Dla organizmów innych niż bakterie, tempo mutacji wynosi pomiędzy 0,01 i 1 na miliard. Przypuszcza się, że przyczyna tej różnicy pomiędzy bakteriami a innymi organizmami związana jest z rozmiarem genomu: bakterie mają mniejsze genomy i mogą w związku z tym wytrzymać wyższe tempo mutacji bez spowodowania katastrofy błędów. [1] Biologiczna replikacja jest ekstremalnie dokładana. Istnieją specjalne mechanizmy pozwalające na eliminację części błędów, lub ich ignorowanie. Jest to niezbędne ponieważ mutacje niszczą istniejące funkcjonalne sekwencje DNA i są przez to niekorzystne (nawet rzadkie korzystne mutacje powodują utratę informacji).
Model realistycznego tempa mutacji pokazuje co się dzieje, kiedy bardziej realistyczne tempo mutacji zastosujemy do symulacji Dawkinsa. Tempo mutacji 1 na 100 000 000 (10 na miliard liter) oznacza, że symulacja potrzebuje o wiele więcej czasu aby osiągnąć założony cel. Dojście do docelowej sekwencji zajmuje jej — przy zastosowaniu typowego peceta — kilka tygodni. Oczywiście, model realistycznego tempa mutacji jest wciąż nierealistyczny biorąc tempo mutacji z przedziału dla bakterii, ale pomaga zilustrować, jak bardzo rzeczywistość odbiega od symulacji Dawkinsa. (Aby korzystać z tego modelu w znośnym dla użytkownika czasie, czas trwania symulacji można znacznie skrócić przez skorzystanie ze specjalnego przelicznika — o tym patrz w rozdziale "Kilka dodatkowych ustawienień dla pasjonatów").
DNA Model (Model DNA)
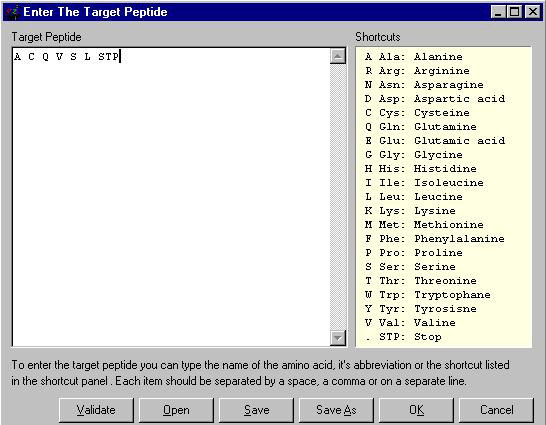
Każdy standardowy podręcznik biochemii opisuje proces syntezy białek na podstawie symbolicznej informacji zawartej w sekwencji DNA. Ten model pozwala nam symulować ewolucję właśnie DNA i co tym idzie syntezowanych aminokwasów. Użytkownik może tworzyć własną dowolną sekwencję aminokwasów — program posiada edytor do tego — i zmieniając różne parametry symulować jej ewolucję z poziomu losowego genomu. Edytor można otworzyć przez wejście w "Edit" --> "Target Peptide" lub przez zaznaczenie opcji "DNA Model" w górnej części Panelu Ustawień po prawej stronie (o tym panelu patrz niżej). Obok okienka "Target" pojawi się przycisk "Edit". Naciskając go, pokaże nam się okno, w którym możemy edytować dowolną sekwencję aminokwasów.
|
Dokonujemy tego w następujący sposób. Najpierw kasujemy pierwotną sekwencję Dawkinsa. Następnie wpisujemy w oknie literowe symbole — oddzielając je spacjami, przecinkami lub znakami / \ — poszczególnych aminokwasów występujących w żywych organizmach. Symbole te i odpowiadające im aminokwasy możemy zobaczyć w tabeli po prawej stronie okna, w którym projektujemy własne sekwencje aminokwasów. Np. chcemy stworzyć sekwencję złożoną z alaniny, cysteiny, glutaminy, waliny, seryny i leucyny. Wpisujemy więc w oknie dużymi lub małymi literami następujące symbole: A C Q V S L. Sekwencję możemy zakończyć symbolem STP, czyli oznaczeniem kodonu STOP, który przerywa syntezę aminokwasu. Wciskamy teraz przycisk "Validate" aby program sprawdził, czy wprowadziliśmy właściwe symbole. Jeśli tak, w oknie pojawią się rozszerzone symbole tych aminokwasów, czyli: AlaCysGlnValSerLeu. Jeśli wprowadziliśmy jakiś błędny symbol, program zaznaczy to odpowiednim komunikatem. Teraz wciskamy "OK" i wybrana przez nas sekwencja aminokwasów pojawia się w okienku "Target". Możemy rozpocząć wirtualną ewolucję naszej białkowej sekwencji.
Jeśli jakąś sekwencję chcemy zachować do dalszych symulacji, to możemy sobie ją zapisać przez "Save As". Później przywracamy tę sekwencję przez "Open". Można w ten sposób tworzyć bazy aminokwasowych sekwencji do testowania ich ewolucji przy różnych parametrach, które możemy definiować w Panelu Ustawień (np. określanie tempa mutacji, ich urozmaicanie przez wprowadzanie insercji i delecji, określenie złożoności, czas trwania generacji itd. — o funkcjach tych ustawień patrz niżej w dziale Panel Ustawień).
Jak zauważycie, symulacja wyświetla naprzemiennie symbole aminokwasów z odpowiadającymi im symbolami kodonów DNA. Czyli dla alaniny, cysteiny, glutaminy, waliny, seryny i leucyny będą to np.: CGCACAGTCCACTCAGAT. Mutacja w kodonie DNA (oznaczona w kolorze czerwonym) przekłada się rzecz jasna na zmianę aminokwasu (choć nie zawsze). W tym modelu w oknie raportu pojawiają się również aminokwasy w kolorze zielonym, znaczy to, że co prawda we fragmencie DNA kodującym ten aminokwas nastąpiła mutacja, jednak aminokwas pozostał niezmieniony. Jest to jeden z elementów realizmu wprowadzonego do symulacji Weasel. Nie każda mutacja w kodzie DNA przekłada się na zmianę budowy docelowego białka. Na poziomie transkrypcji są mechanizmy kontrolne pozwalające zignorować taką mutację. Większość aminokwasów może być również kodowana przez kilka trójnukleotydowych kodonów. Przykładowo jeśli kodon GCU zostanie zmutowany w GCG lub GCA wciąż może on kodować alaninę.
W symulacji Weasel kodon STOP nie może być generowany gdzieś w środku sekwencji. Gdyby tak się zdarzyło, oznaczałoby to zablokowanie powstawania założonej sekwencji aminokwasów.
Omówione cztery podstawowe modele możemy także urozmaicać przez szereg opcji, które znajdują się w Panelu Ustawień.
Panel Ustawień
Panel ten znajduje się po prawej stronie okna wyświetlającego przebieg ewolucji. W Panelu tym możemy wprowadzać nieco realizmu w symulowane ewolucje. Pokazuje on również jak wiele nierealistycznych założeń ulokował Dawkins w swojej symulacji. Patrząc od góry widzimy następujące opcje.
|
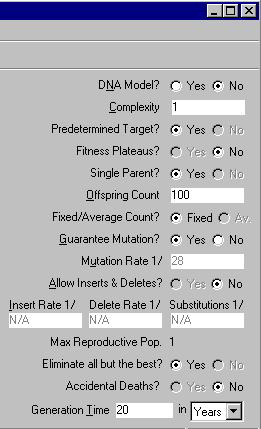
DNA Model? (Model DNA)
Przełącznik ten pozwala przejść do Modelu DNA (gdy zaznaczymy yes). Inną drogą jest wybór Modelu DNA w menu ("Models" --> "DNA Model"). Po uaktywnieniu tego modelu obok okienka "Target" pojawi się przycisk "Edit", przez który możemy wywołać okno służące do definiowania żądanych sekwencji aminokwasów.
Complexity (Kompleksowość)
Opcja Complexity pozwala użytkownikowi określić jak wiele liter docelowej sekwencji (lub aminokwasów) musi się w wyniku mutacji pojawić w jakimś osobniku w bieżącym pokoleniu, by wzrosło "dostosowanie" i by ta sekwencja była selekcjonowana. Umożliwia to zrozumienie faktu, że nie każda pojedyncza mutacja musi mieć wartość adaptacyjną. Czasem konieczne jest jednoczesne wystąpienie dwóch lub więcej takich mutacji, aby dawały one jakąś korzyść i by ta korzyść została "zauważona" przez dobór naturalny.
Dla przykładu z Complexity z zadaną wartością 3, mutant z dodaną jedną właściwą literą nie będzie selekcjonowany, jeśli nie wystąpi druga właściwa litera. Mutant, w którym pojawią się jednocześnie dwie właściwe litery też nie będzie selekcjonowany. Dopiero jeśli trzy właściwe litery (tj. te, które występują w docelowym zdaniu) pojawią się naraz — w jednej generacji — dopiero wtedy nastąpi dalsza selekcja takiego mutanta. Zwróćcie uwagę jak bardzo wydłuża się czas ewolucji gdy choć nieznacznie zwiększymy kompleksowość wybranej sekwencji.
Predetermined Target? (Określenie sekwencji docelowej)
Ta opcja — podobnie jak w symulacji Dawkinsa — jest niedostępna. To kluczowa sprawa w algorytmach ewolucyjnych — cel lub kryteria oceny wyników muszą zostać zdefiniowane przez programistę, to jest algorytm ewolucyjny operuje pod kątem przyszłej funkcji. Aby taki algorytm stworzył jakąś złożoność, najpierw musi zostać do niego wprowadzona informacja konieczna do jej osiągnięcia (więcej na ten temat zobacz w artykule Algorytmy ewolucyjne i inteligentny projekt). W biologicznej rzeczywistości ewolucja nie ma jednak żadnego wcześniej zadanego celu, nie dąży do żadnego długoterminowego celu, tak jak to czyni algorytm ewolucyjny.
Fitness Plateaus? (Płaskowyż dostosowania)
Ta opcja pokazuje kolejne nierealistyczne założenie symulacji Dawkinsa. "Krajobraz" funkcji dostosowania można przedstawić jako górzysty teren. Góry (lokalne maksima) reprezentują dobrze przystosowane populacje. Przystosowanie populacji (fitness) rośnie, jeśli wspina się ona na taką górkę. Co jednak w sytuacji, gdy jakaś populacja zaczyna ewoluować w inną? To znaczy, że musi przejść z jednej górki na drugą. Wtedy część takiej populacji musi oczywiście najpierw zejść we właściwym kierunku ze swojej góry dostosowania. Tyle, że natrafiamy na jeden problem — aby przejść z jednej góry na drugą, trzeba przebyć dolinę między nimi. A dolina w tym wypadku reprezentuje gorsze przystosowanie. Czyli w momencie schodzenia ze wzgórza przystosowanie ewoluującej części populacji będzie malało.
W momencie gdy część populacji znajdzie się w dolinie pomiędzy górami, jej dostosowanie będzie dużo mniejsze niż pozostałej części populacji, która pozostała na górze. A wiadomo co robi dobór naturalny z gorzej dostosowanym osobnikami — eliminuje je. Czyli dobór naturalny działa przeciw tej części populacji, która zaczęła ewoluować. I nie ma znaczenia, że ewoluuje ona we właściwym kierunku. Dopóki nie znajdzie się ona na przeciwległym wznoszącym się stoku góry, dopóty dobór naturalny będzie przeciwdziałał takiej transformacji.
Powstaje pytanie dlaczego dobór naturalny faworyzował ograniczenia dostosowania, gdy gatunek rozpoczynał schodzenie ze swego wzgórza? Dobór naturalny nie jest przecież przewidujący i faworyzuje tylko to, co jest korzystne w danym momencie:
W prawdziwym życiu kryterium doboru jest zawsze chwilowe, dotyczy albo po prostu przetrwania, albo — bardziej ogólnie — sukcesu reprodukcyjnego. (...) "Zegarmistrz" — czyli kumulatywny dobór naturalny — jest ślepy i nie widzi w odległej przyszłości żadnego celu. [2]
W tym programie jednak — podobnie jak w symulacji Dawkinsa — po prostu zignorujemy tę trudność wynikającą z "ukształtowania" terenu dostosowania i założymy, że każdy ruch w kierunku zdefiniowanego celu jest faworyzowany i selekcjonowany. Tak więc ta opcja jest niedostępna.
Single Parent? (Założone rozmnażanie bezpłciowe)
W tej symulacji — podobnie jak w symulacji Dawkinsa — założone jest rozmnażanie bezpłciowe. Rozmnażanie płciowe stwarza inne problemy dla teorii ewolucji. W rozmnażaniu płciowym każdy nowy osobnik dziedziczy połowę materiału genetycznego po matce a połowę po ojcu. Pozwala to na pewną "korektę" błędów — czyli mutacji, które mogą wystąpić w jednej z kopii genomu. To znacząco zwalnia tempo występowania nowych cech w populacji — to kolejny problem dla teorii ewolucji, który tutaj jest ignorowany — ta opcja jest niedostępna.
Offspring Count (Liczba potomstwa)
Ta opcja determinuje jak wiele potomstwa podlegającego selekcji będzie się rozmnażać w każdej generacji. Program automatycznie ustawia dla każdej symulacji liczbę potomstwa na 100, ale ta opcja jest aktywna — możemy sami wprowadzać dowolne liczby. Im większa jest ta liczba, tym większe prawdopodobieństwo wystąpienia korzystnej mutacji, ale także tym więcej trzeba czasu, aby ten nowy wariant genu rozprzestrzenił się w populacji.
Fixed/Average Count? (Stała liczba potomstwa)
Ta opcja jest niedostępna. Wybrana w Offspring Count liczba potomstwa w trakcie symulacji będzie stała i nie będzie się zmieniać — co ilustruje kolejne nierealistyczne założenie symulacji Dawkinsa.
Guarantee Mutation? (Ściśle określone tempo mutacji)
W Modelu Dawkinsa była tylko jedna mutacja w jednym osobniku na pokolenie. Jedyna dopuszczona przypadkowość to wybór, jaka litera na jakiej pozycji będzie zmieniona i w jaką się zmieni. Oczywiście, tak nie jest w realnym świecie. W jakimś pokoleniu mogą wystąpić dwie i więcej mutacji, lub ani jedna. Kiedy tempo mutacji nie jest stałe, liczba generacji potrzebnych do osiągnięcia docelowej sekwencji wzrasta. Jeśli więc włączymy tę funkcję (yes) program automatycznie ustali tempo mutacji na jedną literę w każdej generacji lub jeden nukleotyd w sekwencji aminokwasów — w każdej generacji w każdym osobniku wystąpi dokładnie jedna przypadkowa mutacja w przypadkowym miejscu. (W Modelu Dawkinsa ta opcja jest automatycznie ustawiona.) Gdy ta funkcja jest wyłączona (no), dopuszczona jest możliwość, że w jakimś pokoleniu wystąpi kilka mutacji w danej sekwencji, a w następnym — żadna. Gdy wyłączymy tę opcję, możemy przejść do ustalenia tempa mutacji (patrz poniżej). Jest to kolejny element realizmu wprowadzony do tego ewolucyjnego algorytmu.
Mutation Rate 1/ (Tempo mutacji)
Tempo mutacji determinuje z jaką częstotliwością będą one występowały w kolejnych pokoleniach. Gdy opcja Guarantee Mutation? jest włączona (on) nastąpi tylko jedna mutacja w jednym osobniku w każdym pokoleniu — niezależnie od długości zadanej sekwencji. Program przeliczy liczbę wprowadzonych przez nas liter lub aminokwasów i na tej podstawie określi stałe tempo mutacji — jedna na jedną sekwencję w każdym pokoleniu. Gdy Guarantee Mutation? jest wyłączona (no) wtedy można samemu ustalać tempo i częstotliwość mutacji wpisując żądaną wartość w pole. Ta opcja pozwala poeksperymentować z szybkością mutacji, pokazując np. jakie tempo mutacji dla jakiej sekwencji spowoduje ugrzęźnięcie symulacji w katastrofie błędów.
Allow Inserts & Deletes? (Wprowadzanie insercji i delecji)
W przyrodzie występują trzy rodzaje mutacji: substytucje (podstawienia), gdzie jeden nukleotyd jest zamieniamy na inny, insercje, czyli wstawienia nowych nukleotydów i delecje — mutacje eliminujące jakiś nukleotyd. Model Dawkinsa uwzględniał tylko jeden rodzaj mutacji — substytucje. Opcja Allow Inserts & Deletes? pozwala użyć dwóch pozostałych rodzajów mutacji: insercji i delecji i określić tempo ich pojawiania się. Jeśli ta opcja jest wyłączona (no) jedynym rodzajem dostępnej mutacji jest substytucja. Następuje ona wtedy, gdy jedna litera (lub nukleotyd) jest zastępowana przez inną — przypadkowo wybraną i w przypadkowym miejscu w sekwencji. Delecja usuwa literę (lub nukleotyd) z miejsca w sekwencji. Insercja dodaje jakąś losowo dobraną literę (lub nukleotyd) w losowe miejsce w sekwencji. W okienkach "Insert Rate 1/" i "Delete Rate 1/" możemy wprowadzać żądane wartości ustalając tym samym tempo insercji i delecji (możemy także używać liczb dziesiętnych np. 0,5 czy 0,4). W trzecim okienku "Substitutions 1/" pojawiają się natomiast automatycznie przeliczane proporcje tych trzech typów mutacji wykorzystanych w symulacji (w to okienko nic nie możemy wpisać, służy ono tylko do odczytu proporcji mutacji). Aby symulacja ruszyła skalkulowana liczba nie może być mniejsza niż 1.
Dla przykładu jeśli tempo insercji ustawimy 1 na 4 (1/4) znaczy, że jedna na cztery mutacje będzie wstawiająca. Jeśli następnie dla delecji wprowadzimy liczbę 3 (1/3), wtedy program automatycznie przeliczy stosunek tych trzech rodzajów mutacji na 1/2,4. Tę opcję możemy stosować, gdy Guarantee Mutation? jest zaznaczone na no. Została ona dodana by wprowadzić elementy realizmu w symulacji Weasel.
Użytkownik musi zachować nieco rozsądku w wyborze każdej z tych wartości. Dla przykładu jeśli zadamy wysokie tempo insercji i jednocześnie niskie tempo delecji przy wysokim tempie mutacji, ewoluująca sekwencja zacznie się szybko rozrastać, coraz mniej przypominając sekwencję docelową. Ewolucja takiej sekwencji wpadnie w inną odmianę katastrofy błędów.
Max Reproductive Pop. (Reprodukuje się tylko jeden osobnik)
W tej symulacji — za programem Dawkinsa — ta opcja jest niedostępna — ustalona na 1. Chociażby liczba potomstwa była ustalona na 1000 tylko jeden osobnik (czyli sekwencja liter lub aminokwasów) zostaje wyselekcjonowany do dalszej reprodukcji.
Eliminate all but the best? (Eliminacja wszystkich oprócz idealnie dopasowanych)
Nie ma możliwości wyboru tej opcji — podobnie jak w symulacji Dawkinsa. Jest ona zadana i znaczy, że selekcja operuje z absolutną skutecznością. Jeśli jakaś sekwencja pasuje do docelowej w 100% — to tylko taka przeżyje, wszystkie inne sekwencje nie pasujące choćby jedną literą będą uznane, jako pasujące do docelowej sekwencji w 0% — żadna z nich nie przeżyje. Oczywiście to zupełnie nierealistyczne. W realnym świecie współczynnik ten wynosi około 0.01. Jeśli jednak zostałoby to uwzględnione, liczba generacji koniecznych do osiągnięcia docelowej sekwencji kolosalnie wzrosłaby, czego — jak widać — algorytmy ewolucyjne tego rodzaju zupełnie nie biorą pod uwagę.
Accidental Deaths? (Możliwość przypadkowej śmierci jest zignorowana)
W realnym świecie selekcyjna korzyść nie gwarantuje jeszcze przetrwania, kiedy np. zdarzają się katastrofy w rodzaju powodzi, pożarów, gwałtownych zmian klimatu itp. Ta symulacja — podobnie jak symulacja Dawkinsa — zakłada, że nasz hipotetyczny organizm nigdy nie znajdzie się w niewłaściwym czasie i niewłaściwym miejscu.
Generation Time (Czas trwania generacji)
Tutaj można ustalać czas życia generacji na lata, dni, godziny i minuty. Program przelicza zadane wartości i w Panelu Wskaźników ("Years" — patrz niżej) podaje czas (w przeliczeniu na lata) jaki mija w trakcie naszej hipotetycznej ewolucji. W lewym oknie wpisujemy liczbę, a w prawym wybieramy, czy mają to być lata, dni, godziny czy minuty.
Zapisywanie ustawień
Jeśli chcemy testować różne ewolucje przy tych samych ustawieniach, jakie sami wprowadziliśmy, możemy zapisać taki zespół ustawień. Możemy skorzystać z tej możliwości wchodząc w głównym menu do "Models". Pod czterema podstawowymi modelami programu znajdują się opcje zapisu. "Save Settings" pozwala zapisać bieżące ustawienia. Opcja "Open Settings" pozwala przywrócić te zapisane przez nas ustawienia. W tym wypadku wystarczy otworzenie takiego pliku, a program automatycznie skasuje bieżące ustawienia i zastąpi je tymi zapisanymi w pliku.
Panel Wskaźników
|
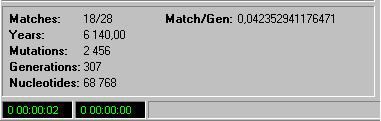
Panel ten znajduje się pod oknem wyświetlającym przebieg ewolucji. Pokazuje on kilka parametrów przebiegającej symulacji. Wyświetla następujące dane:
Matches:
Czyli dopasowanie. Wskaźnik ten pokazuje ile bieżących liter (lub aminokwasów) pasuje do docelowej sekwencji. Dzięki temu wskaźnikowi możemy śledzić jak szybko symulacja podąża do docelowej sekwencji, a także bardzo ładnie obserwować do jakiego poziomu dopasowania dotrze zanim np. ugrzęźnie w katastrofie błędów.
Match/Gen:
Wskaźnik ten na bieżąco przelicza średnią dopasowania do sekwencji docelowej dla każdej generacji.
Years:
Ten wskaźnik podaje, jak liczba generacji przekłada się na liczbę lat. Zależy to rzecz jasna jaką zadamy długość trwania każdej generacji (patrz Panel Ustawień — czas generacji).
Mutations:
Tutaj możemy sprawdzić ile nastąpiło mutacji w aktualnej symulacji.
Generations:
Wskaźnik ten pokazuje liczbę generacji w aktualnej symulacji.
Nucleotides:
Ten wskaźnik umożliwia obliczenia tempa mutacji. Porównanie "Mutations/Nucleotides" pozwala określić tempo mutacji w bieżącej symulacji.
Zegary
Na samym dole znajdują się dwa zegary. Wyświetlane w nich cyfry są czerwone — jeśli symulacja jest nieaktywna — i zielone, jeśli symulacja jest w toku lub jest w trakcie pauzy. Gdy symulacja dobiegnie końca, także zmieniają one kolor z zielonego na czerwony. Zegar lewy wyświetla ogólny czas biegnącej symulacji, zegar prawy pokazuje czas, od kiedy wartość "Matches", czyli dopasowania do docelowej sekwencji zmieniła się.
I kilka dodatkowych ustawień dla pasjonatów
Pasjonaci ewolucyjnych algorytmów mają do dyspozycji kilka dodatkowych ustawień pozwalających np. na dokumentowanie wyników symulowanych ewolucji.
Dokumentowanie przebiegu symulacji
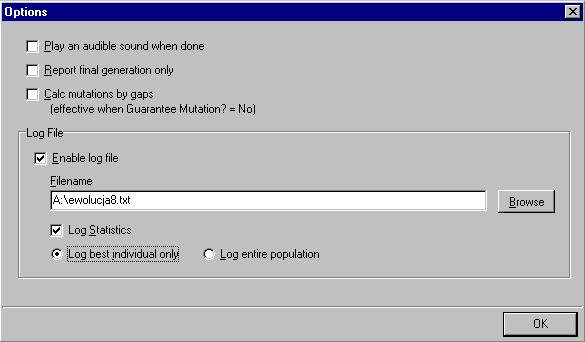
|
Jeśli chcemy zapisać przebieg jakiejś symulowanej ewolucji tekstu lub sekwencji aminokwasów, program posiada opcję umożliwiającą generowanie i zapisywanie statystyk dla każdej generacji. Aby uaktywnić tę opcję wchodzimy w menu "Edit" do "Options". W oknie dialogowym zaznaczamy następnie "Enable log file". W oknie "Filename" musimy teraz nadać jakąś nazwę pliku, w którym będzie zapisywany przebieg symulacji (wraz ze ścieżką dostępu do katalogu, gdzie chcemy ulokować ten plik). Możemy także użyć przycisku "Browse" do wybrania wcześniej utworzonego pliku — ale uwaga — koniecznie tekstowego (txt). Dodatkowo możemy uaktywnić opcję "Log statistic", dzięki której dla każdej generacji będą zapisywane takie wartości jak liczba lat, generacji i mutacji. Tutaj mamy także do wyboru dwie opcje: "Log best individual" i "Log entire population". Pierwsza zapisuje ewolucję tylko najlepszych osobników w populacji, druga zapisuje ewolucję wszystkich osobników w populacji.
Format generowanego pliku zapisującego ewolucję jest tekstowy, także można go później bez problemu otworzyć z dowolnego edytora tekstu. Uważajcie przy tej opcji — jeśli jest ona aktywna program zwalnia modelowanie ewolucji ciągle zapisując wszystkie symulacje. Jeśli są one długie i złożone, pliki tekstowe będą bardzo duże.
Akcelerator modelu realistycznych mutacji
Model realistycznych mutacji możemy sztucznie przyspieszyć korzystając ze specjalnego algorytmu, który przelicza wykładniczą dystrybucję prawdopodobieństwa mutacji. Aby go uaktywnić wchodzimy do "Edit" --> "Options" i tu zaznaczamy "Calc mutations by gaps".
Wyświetlanie tylko ostatniej generacji
Okno raportu wyświetlające przebieg ewolucji może wyświetlić tylko ostatnią generację całej symulacji. Aby uaktywnić tę opcję wchodzimy do "Edit" --> "Options" i zaznaczamy tu "Report final generation only".
Dźwiękowy sygnał na zakończenie symulacji
Jeśli chcemy, by program informował nas odpowiednim sygnałem gdy aktualna symulacja dobiegnie końca, możemy wejść w "Edit" --> "Options" i zaznaczyć "Play an audible sound when done".
Zmiana ustawień generatora losowych liczb
Losowym doborem liczb w symulacji Waesel, koniecznym do generowania przypadkowych mutacji, steruje specjalny algorytm (The Mersenne Twister Pseudo-Random Number Generator). Ten generator przy każdym uruchomieniu programu przesiewa losowo liczby z takim samym tempem w każdej symulacji. Jest to zrobione w tym celu, aby testy mogły być powtarzane, np. w celu porównywania wyników. Aby to zmienić, mamy do dyspozycji dwie opcje. Możemy je uruchomić wchodząc do "Random Numbers" w głównym menu. Przez opcję "Randomize" sprawiamy, że generator losowych liczb dobiera liczby korzystając z systemu zegara. Możecie używać tej opcji w celu urozmaicania wyników symulowanych ewolucji.
Druga opcja — "Use Random Seed" umożliwia zmianę tempa przesiewania liczb — np. jeśli chcecie testować jakąś symulację przy różnym tempie przesiewania — bez konieczności każdorazowego restartowania programu. Po wywołaniu tej opcji, ukaże się nam okienko, w którym możemy wpisać żądane wartości prędkości przesiewania (możemy wpisywać tylko liczby całkowite).
Podsumowanie
Symulacja Dawkinsa nie może służyć jako pokaz potęgi doboru kumulatywnego z dwóch zasadniczych względów:
- Końcowa sekwencja METHINKS IT IS LIKE A WEASEL została z góry zadana, a deterministyczny algorytm gwarantuje jej osiągnięcie. Program Dawkinsa nie tworzy żadnej nowej informacji, a tylko powiela tę, która została do niego wcześniej rozumnie wprowadzona.
- Jego symulacja bazuje na wielu nierealistycznych założeniach, które faworyzują "ewolucję". Gdy rozmaite parametry symulacji Dawkinsa ulegną zmianie, samemu można zobaczyć, jak precyzyjnie dobrał on wartości tych parametrów, aby prowadziły one do celu.
Algorytm ewolucyjny Weasel pokazuje to wszystko w prosty, demonstracyjny sposób.
Opracowanie Michał Ostrowski
Przypisy
[1] Zob. A. R. Fersht, DNA replication fidelity, Proceedings of the Royal Society (London) 1981, B212, s. 351-379; J. W. Drake, Comparative rates of spontaneous mutation, Nature 1969, vol. 221, s. 1132; J. W. Drake, Spontaneous mutation, Annual Reviews of Genetics 1991, vol. 25, s. 125-146.
[2] Richard Dawkins, Ślepy zegarmistrz czyli, jak ewolucja dowodzi, że świat nie został zaplanowany, Biblioteka Myśli Współczesnej, Państwowy Instytut Wydawniczy, Warszawa 1994, s. 92.